Content
This guide explains how to build a RAG system step by step, from scoping your first knowledge domain to deploying assistants that answer with citations. If you want to build a RAG system that works in production, the fundamentals are: clean knowledge, sensible chunking, strong retrieval, and continuous evaluation. Here is the complete process..
If you want the full overview of RAG concepts and patterns first: RAG AI Guide →
What you need before you build a RAG system
Pick one knowledge domain to start
Start with a single domain where “wrong answers” are costly and documents exist:
- onboarding policies
- support macros and troubleshooting docs
- operational SOPs
- product documentation
A narrow scope helps you ship faster and measure quality.
Assemble a small, clean knowledge set
RAG quality depends on knowledge hygiene. Before you ingest:
- remove obvious duplicates
- identify “source of truth” docs
- separate outdated versions (or label them clearly)
Define what “good” means
Write 15–30 real questions your users ask today. These become your test set. You’ll use them to evaluate retrieval and answer quality after every change.
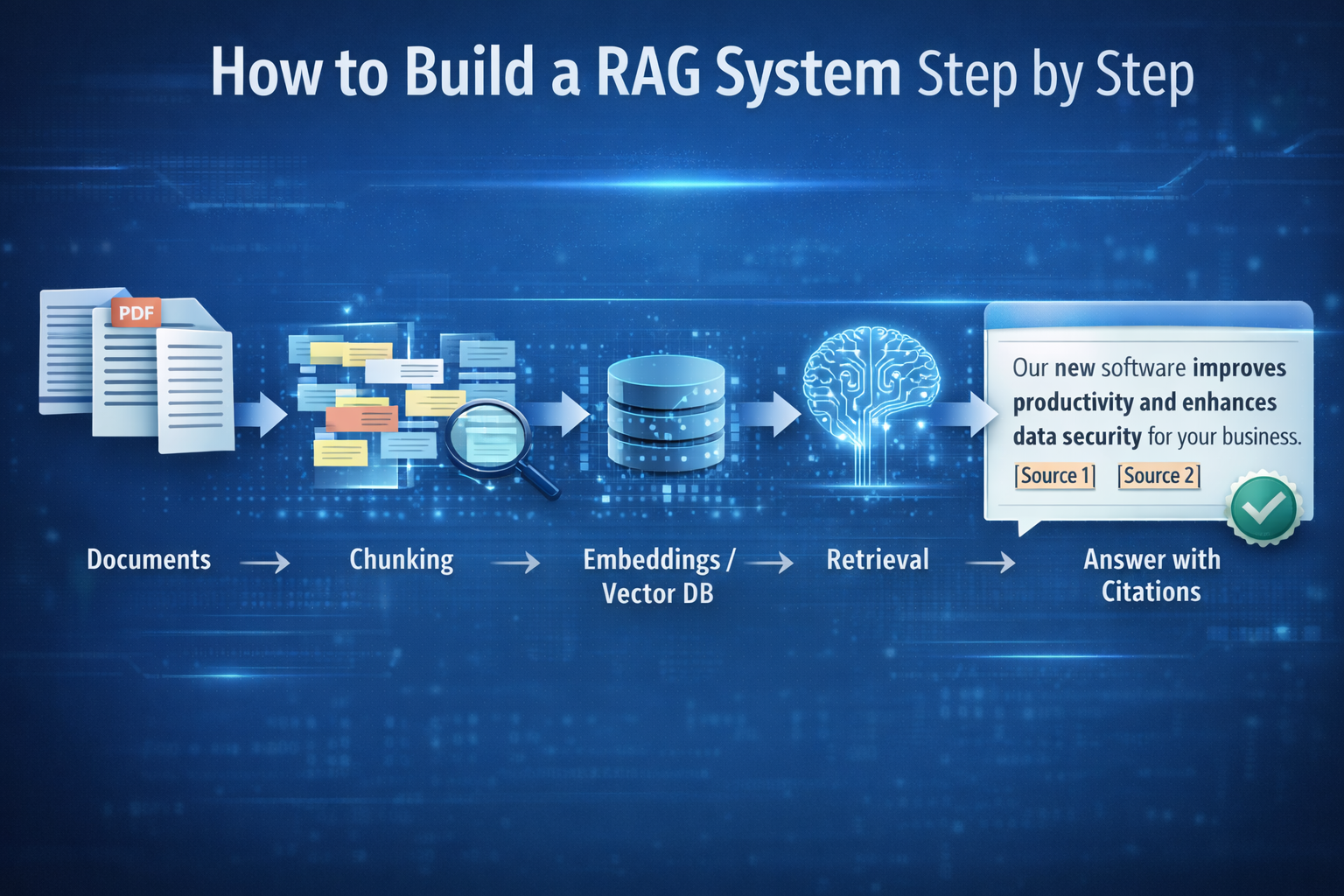
How to create a RAG system
Step 1: Ingest documents and extract text
Bring in your PDFs, docs, wikis, and knowledge pages. Ensure the extracted text is readable and consistent. If your documents are scanned images, you’ll need OCR before RAG can work well.
Step 2: Chunk the content and add metadata
Chunking is where many RAG systems fail.
Your chunks should:
- be small enough to retrieve precisely
- be large enough to contain meaningful context
- carry metadata like source, title, section, last updated, owner
Metadata becomes critical later for governance and citations.
Step 3: Create embeddings and store them
Embeddings represent meaning. You generate embeddings for each chunk and store them in a vector index (often a vector database). This enables semantic retrieval when wording differs between the question and the document.
Step 4: Build retrieval that actually finds the right evidence
At minimum, implement semantic retrieval. In many business cases, you’ll get better results with:
- hybrid retrieval (keyword + semantic)
- simple re-ranking (to improve relevance ordering)
Retrieval quality is the biggest lever in RAG performance.
Step 5: Write the answer prompt with grounding rules
Your RAG prompt should explicitly require:
- answer only using the provided context
- cite sources
- if context is insufficient, say you don’t know (or ask a clarifying question)
This is how you reduce hallucinations in practice.
Step 6: Generate answers with citations
When the model answers, include citations or references to the chunks used. This is what makes RAG “business-safe”: users can verify where answers came from.
A minimal RAG architecture you can ship fast
MVP pipeline
- documents → text extraction
- chunking + metadata
- embeddings + vector index
- retrieval (top-k chunks)
- LLM answer using retrieved context
- citations + refusal behavior
Don’t overbuild early
Avoid multi-agent complexity, tool chains, or advanced orchestration until you can consistently answer your test questions well.
If you want the same pipeline without building from scratch. BrainPack Product →
How to evaluate your RAG system
Test retrieval first
Before judging the LLM, check whether the right evidence is being retrieved. For each test question, ask:
- Did the top results include the correct source?
- Was the evidence complete enough to answer?
If retrieval is wrong, the model’s answer will be wrong.
Measure answer quality
For answers, evaluate:
- groundedness (no claims beyond evidence)
- correctness (matches the source)
- citation accuracy (citations support statements)
- completeness (addresses the question fully)
Track operational metrics
In production you also care about:
- latency (time to answer)
- cost per query
- failure rates (no evidence retrieved, refusals)
- freshness (how quickly new docs become searchable)
If you want to compare plans before you start: Pricing →
Common failure points when building RAG
Poor chunking
Chunks that are too big become vague; too small lose context. If your answers feel “close but not quite,” chunking is often the cause.
Conflicting sources
If your knowledge base contains multiple versions of truth, RAG will surface contradictions. You need governance: ownership, versioning, and document lifecycle rules.
No maintenance loop
RAG isn’t “set and forget.” You need a routine to:
- ingest updates
- remove stale sources
- re-index regularly
- monitor performance on test questions
How Brainpack relates to building RAG
RAG is the foundation. Brainpack packages that foundation into an operational workflow teams can govern and reuse—so you can deploy reliable knowledge engines faster. Brainpack Product →
If you haven’t read the business framing yet:
Beyond the Hallucination →
Conclusion
To build and create a RAG system that works in the real world, focus on the fundamentals: clean knowledge, sensible chunking, strong retrieval, strict grounding rules, and continuous evaluation. Most “RAG problems” are retrieval and knowledge problems—so fix those before adding complexity.
Next steps
- Go deeper: RAG AI Guide →
- See the packaged workflow: Brainpack Product →
- Choose a plan. Pricing →